Stray characters
I have tried to merge all my photo collections in a single place for months. Photo storage services make data export incredibly frustrating. Some services send you images and metadata in different files, and it is up to you to merge that information.
Flickr is one of those services. Their data export was waiting in my Downloads folder for weeks, and today I decided it was time to cross this task from the list. After a bit of JavaScript and some ExifTool magic, I got over 1200 pictures ready for review.
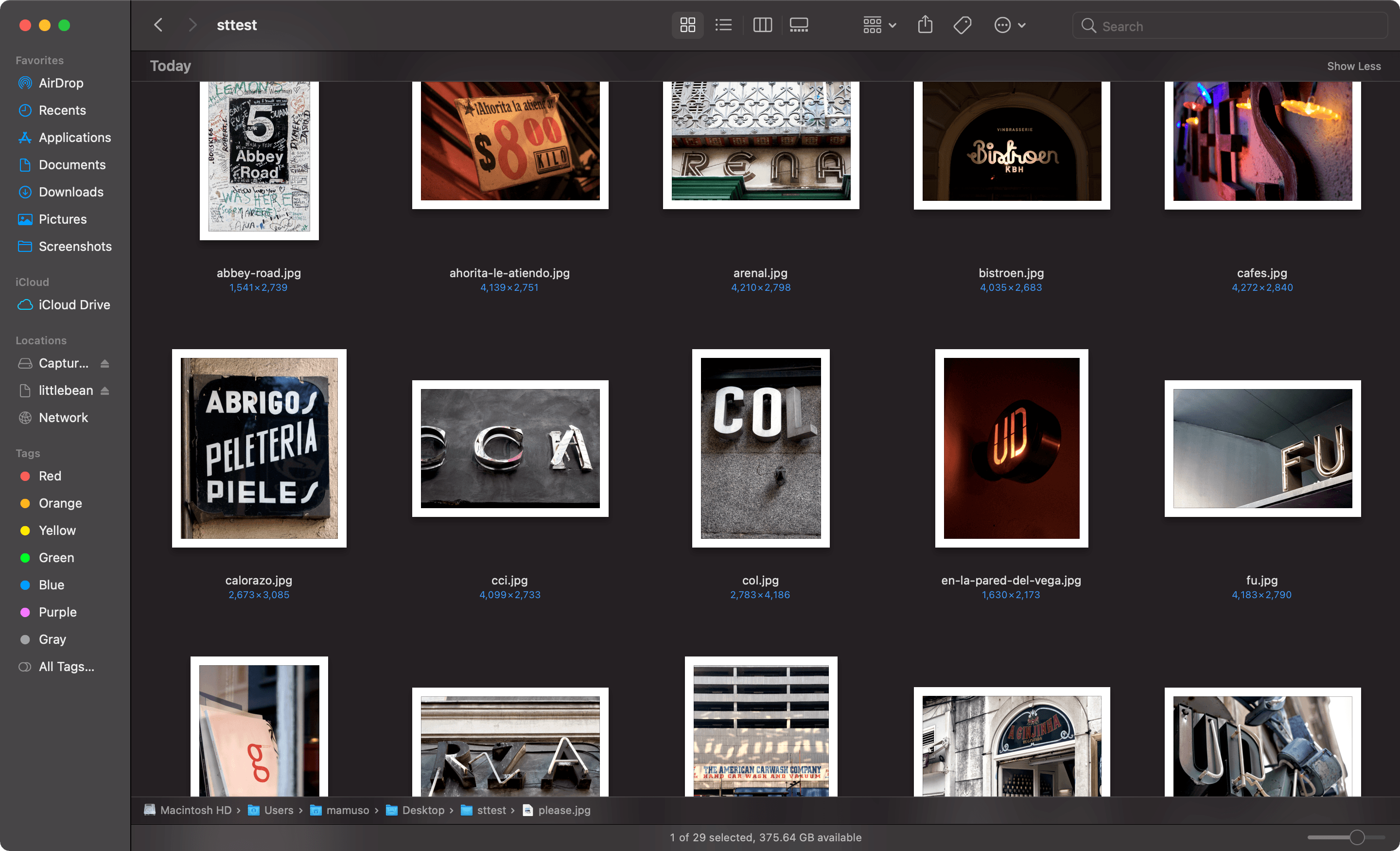
I rediscovered that, between 2005 to 2014, I took a good amount of pictures of urban typography.
I know how it started. Back in 2003, I got a copy of America Sánchez’s Barcelona Gráfica. The book clusters lettering, typography, and signals that represent the character of the city. I liked the idea of treating the urban environment as a graphic canvas.
I don’t know why I stopped, though. I enjoyed the letter hunting and still enjoy those pictures, so I created a silly site.
{kind=link}
{kind=link}