Listing screenshots
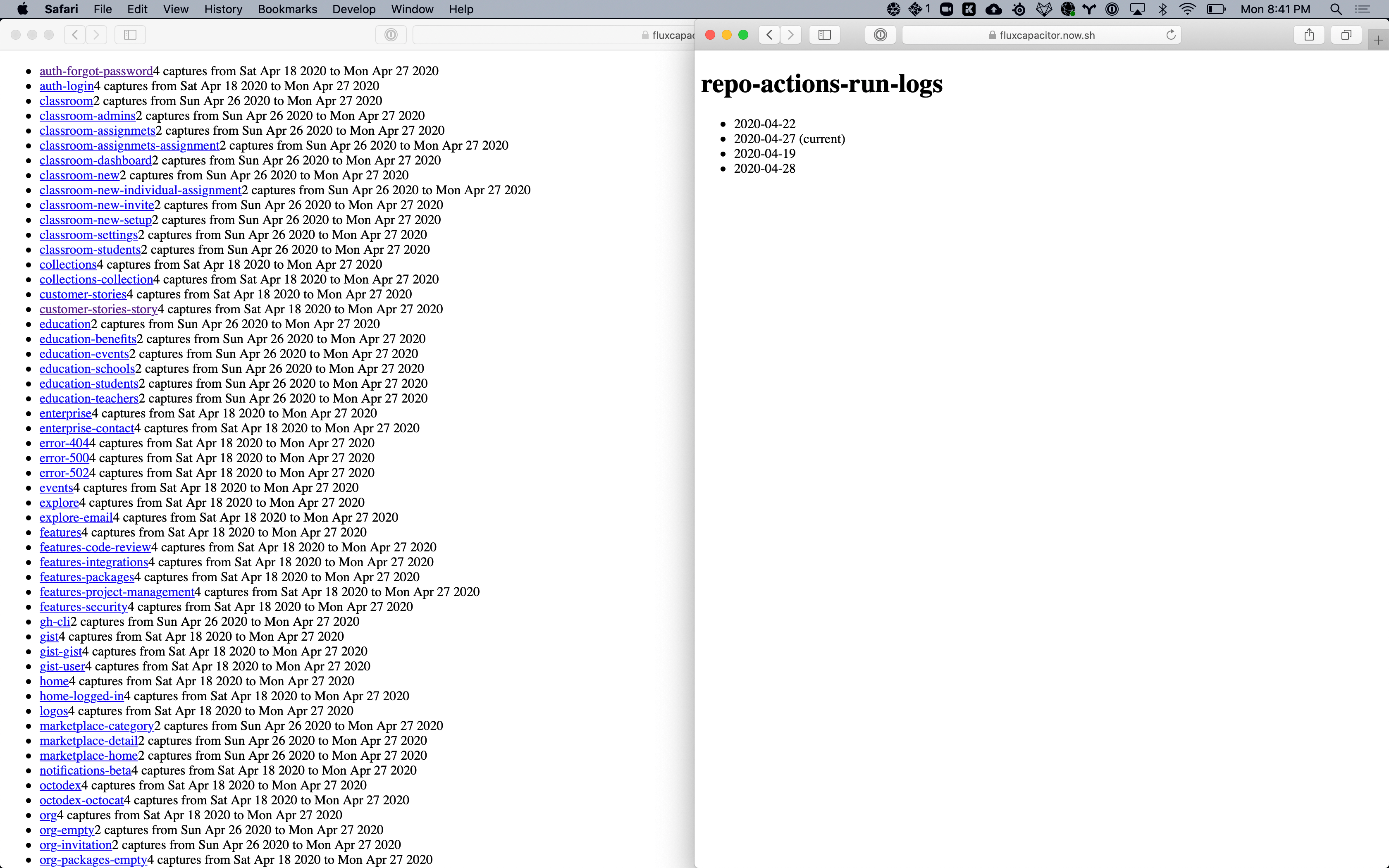
I started to work on the scaffold of the different pages that I'm going to need to present the screenshots. I'm using nextjs and prisma behind the scenes.
I started to work on the scaffold of the different pages that I'm going to need to present the screenshots. I'm using nextjs and prisma behind the scenes.
I spent most of the weekend working on breaking the paparazzi pipeline into pieces. It turns out that trying to run all the steps in a single process doesn't scale well, and the process stalls when we have many URLs in the config.
I drafted a first potential interface for consuming the screenshots. Not terribly happy about it, but we need to start somewhere.
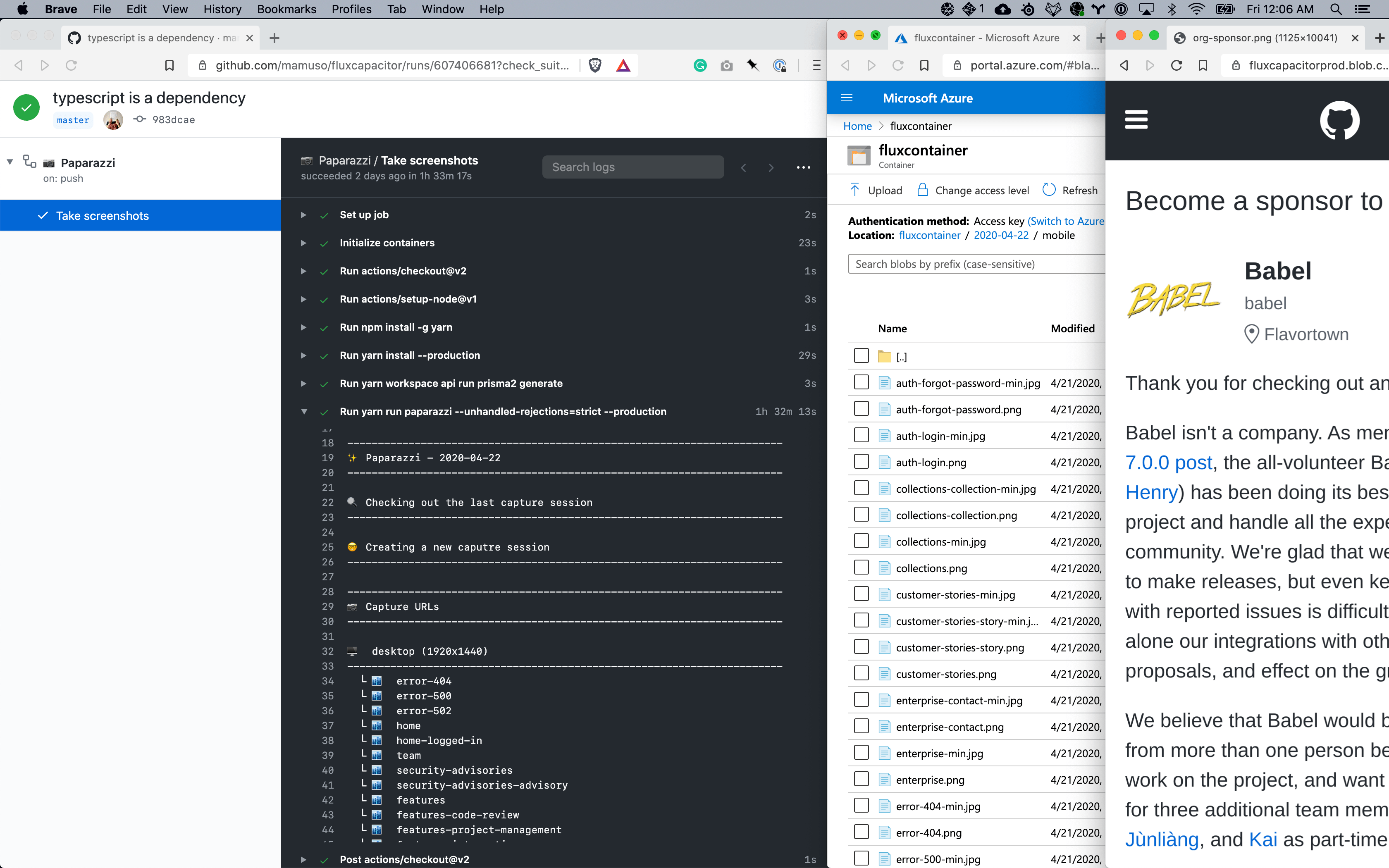
WELL, WELL! Fluxcapacitor (formerly Timesled, I'm the worst naming projects) runs like a charm over GitHub Actions, and I rewrote a big chunk of the code for sustainability:
The infra is more sophisticated than a few months ago. The images and the tgzs of the captures are blobs in Azure, and Prisma2 handles the data layer.
I'm really happy with the progress so far :)
Today I don't feel like coding a lot, so I'm crossing one of the easy issues that I had on my list. I prepared a simple nextjs scaffold and deployed it to
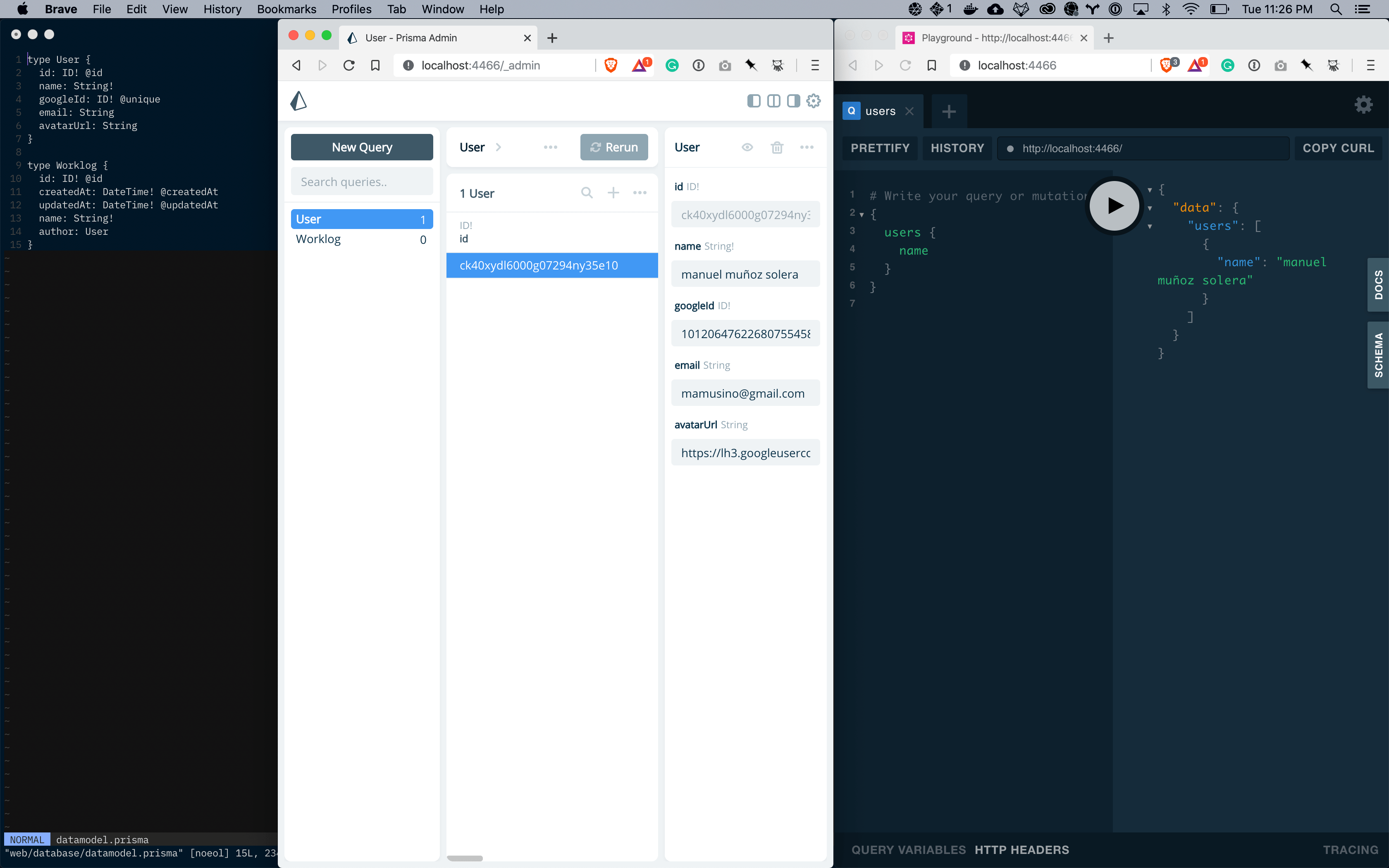
Why would you want a side project if you can have two :trollface:.
I'm starting to work with Adrián on transforming the concept of this work feed into a real product. I'll be writing a lot more about it while we build it.
We want to have something ready to ship very fast, so we are using Max Stoiber and Brian Lovin's product boilerplate as our initial foundation. I'm thoroughly impressed by how fast we were able to go from nothing to start working on our data model.
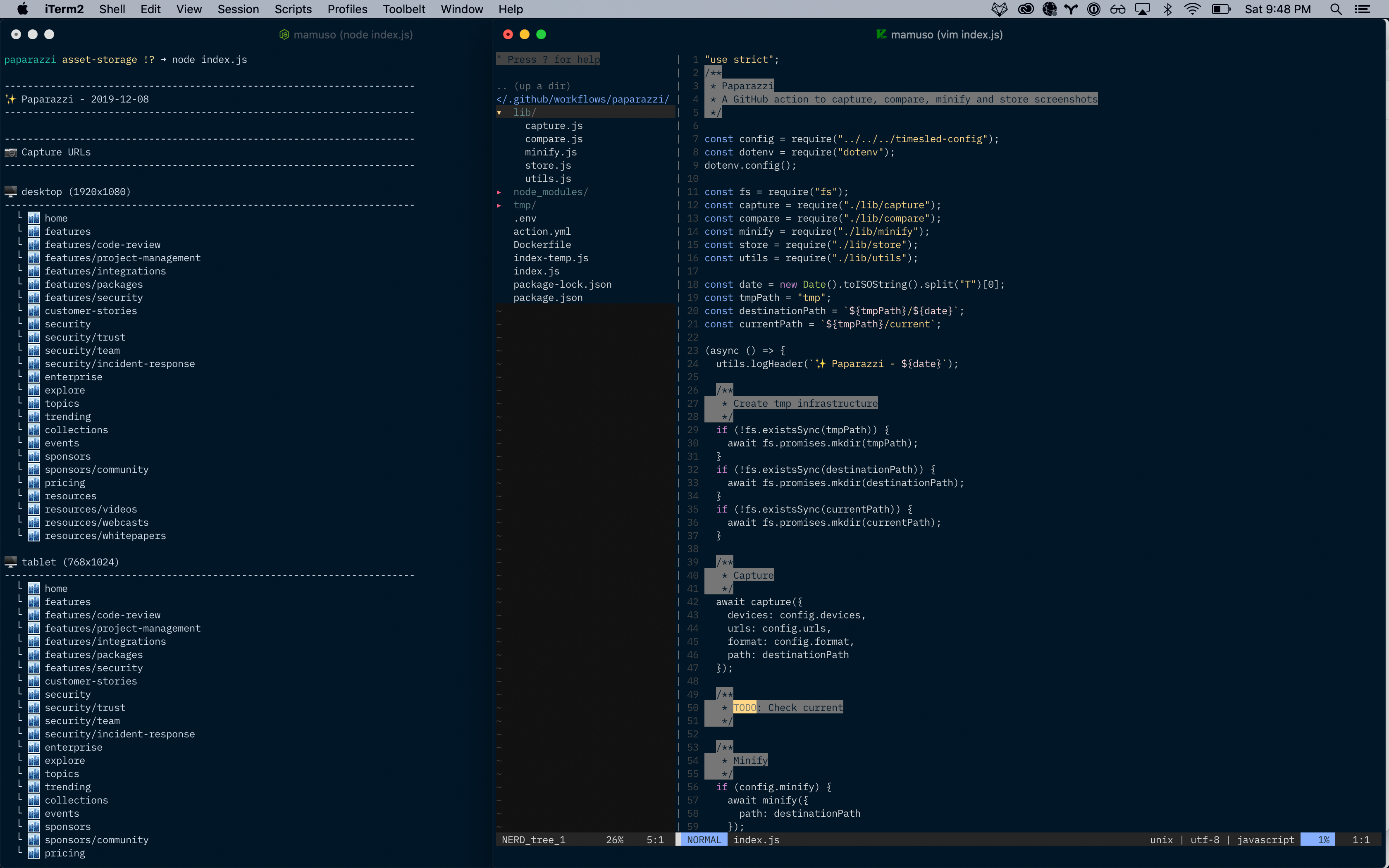
Today was cleanup time. I broke a gigantic index.js into manageable pieces and tried to tidy some of the mess that I did while I was building the concept.
I made some progress with the storage, and I have a few ideas for abstracting different providers. I'd love to start capturing three times a week to have data for feeding the frontend of the project.
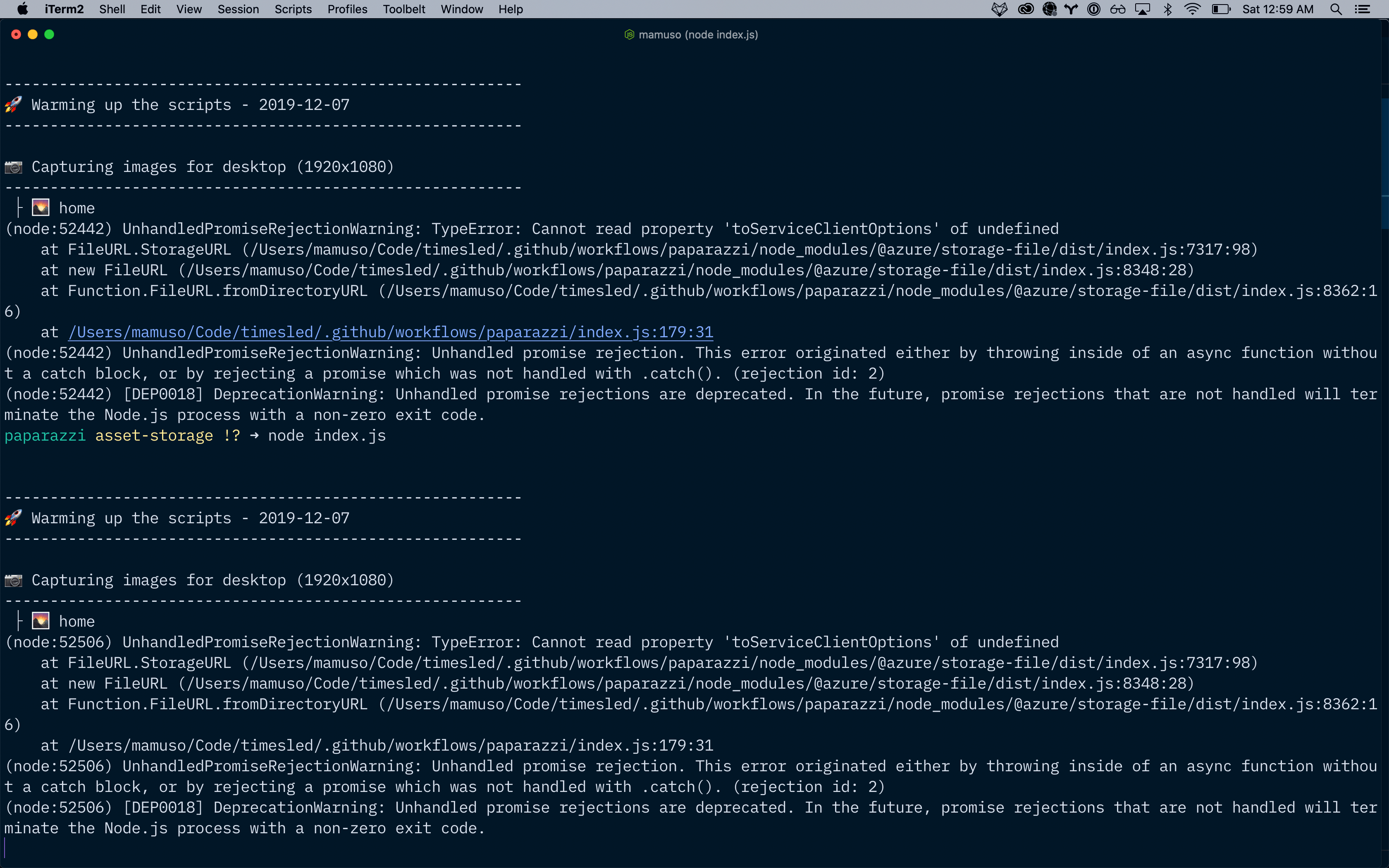
Got stuck in a potentially stupid thing, and wrote a bunch of spaghetti code that I'll need to throw away tomorrow.
On the bright side, I think that I understand a lot better how to deal with AzStorage. 🤷🏼♂️
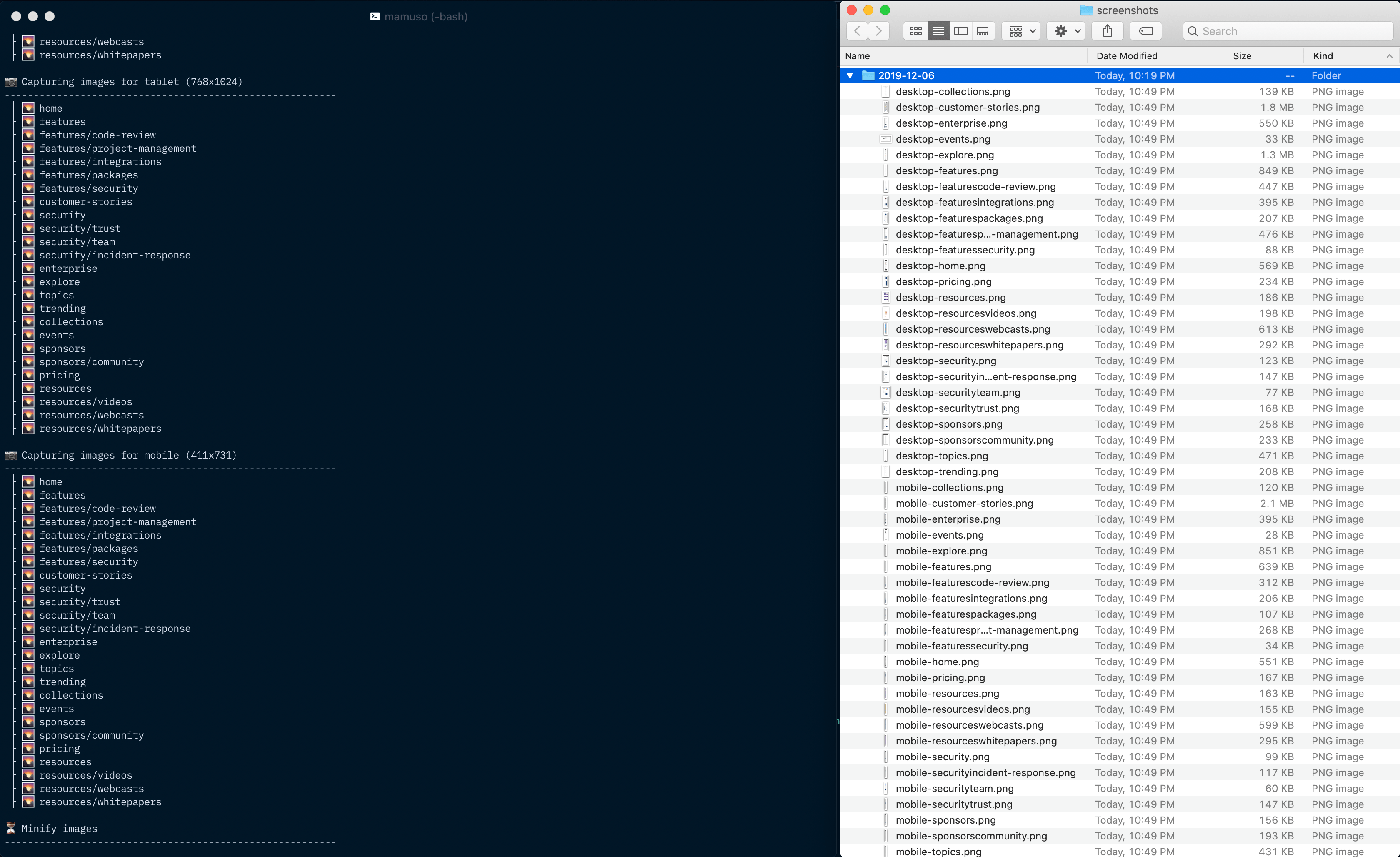
The action now iterates over a few devices and a list of URLs. It is slow, but that was expected.
I'm worried about the size of each run, to the point where I'm considering implementing the storage layer straight away. I also implemented minification, but I wonder if it is going to mess with pixelmatch.
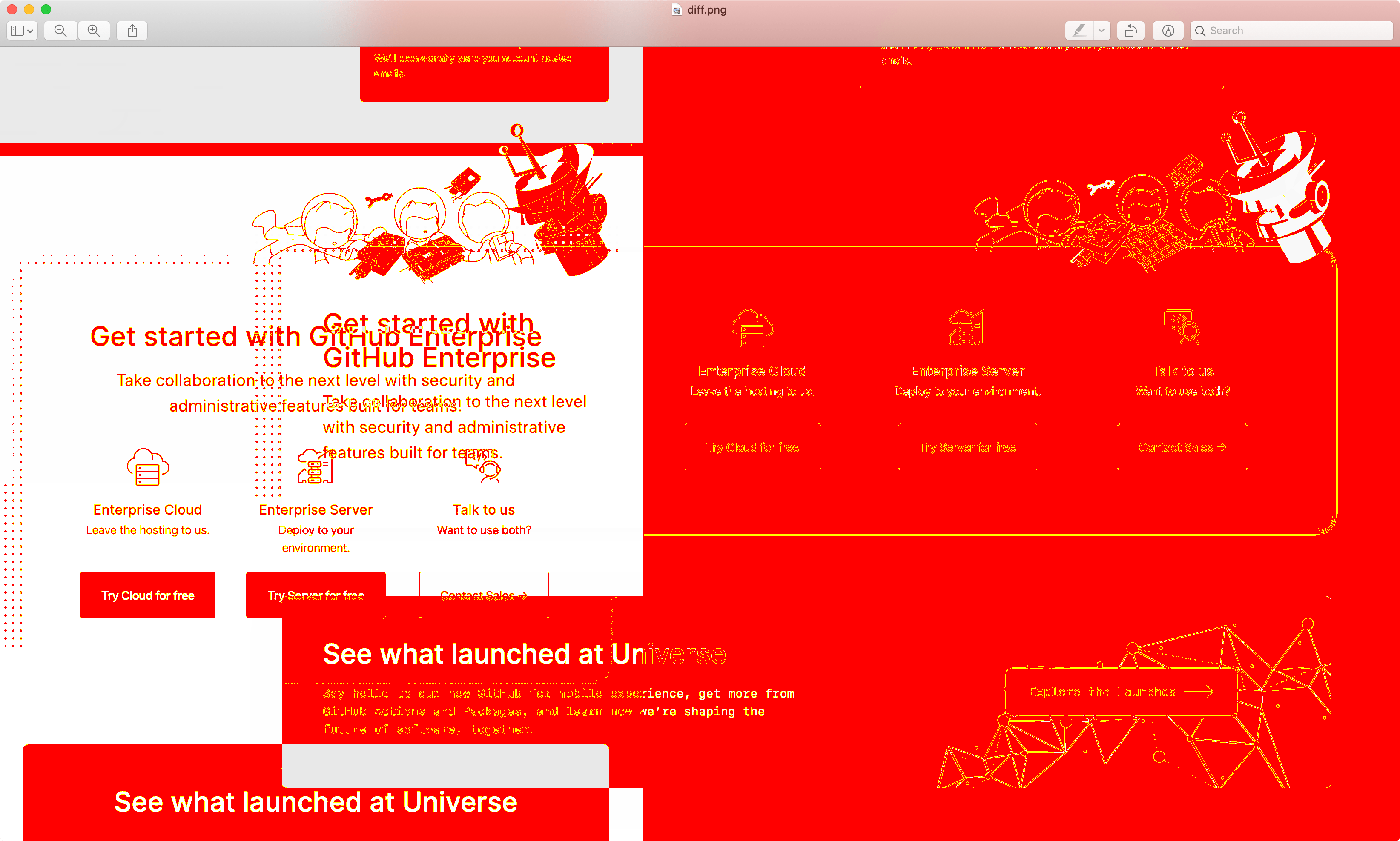
I played today with pixelmatch. I want to detect differences between screens from day to day.
One of the challenges of using pixelmatch is the difference in sizes when you are capturing full screen websites. If the images don't match in size, the script raises an error. I have been writing some code to overcome that problem.
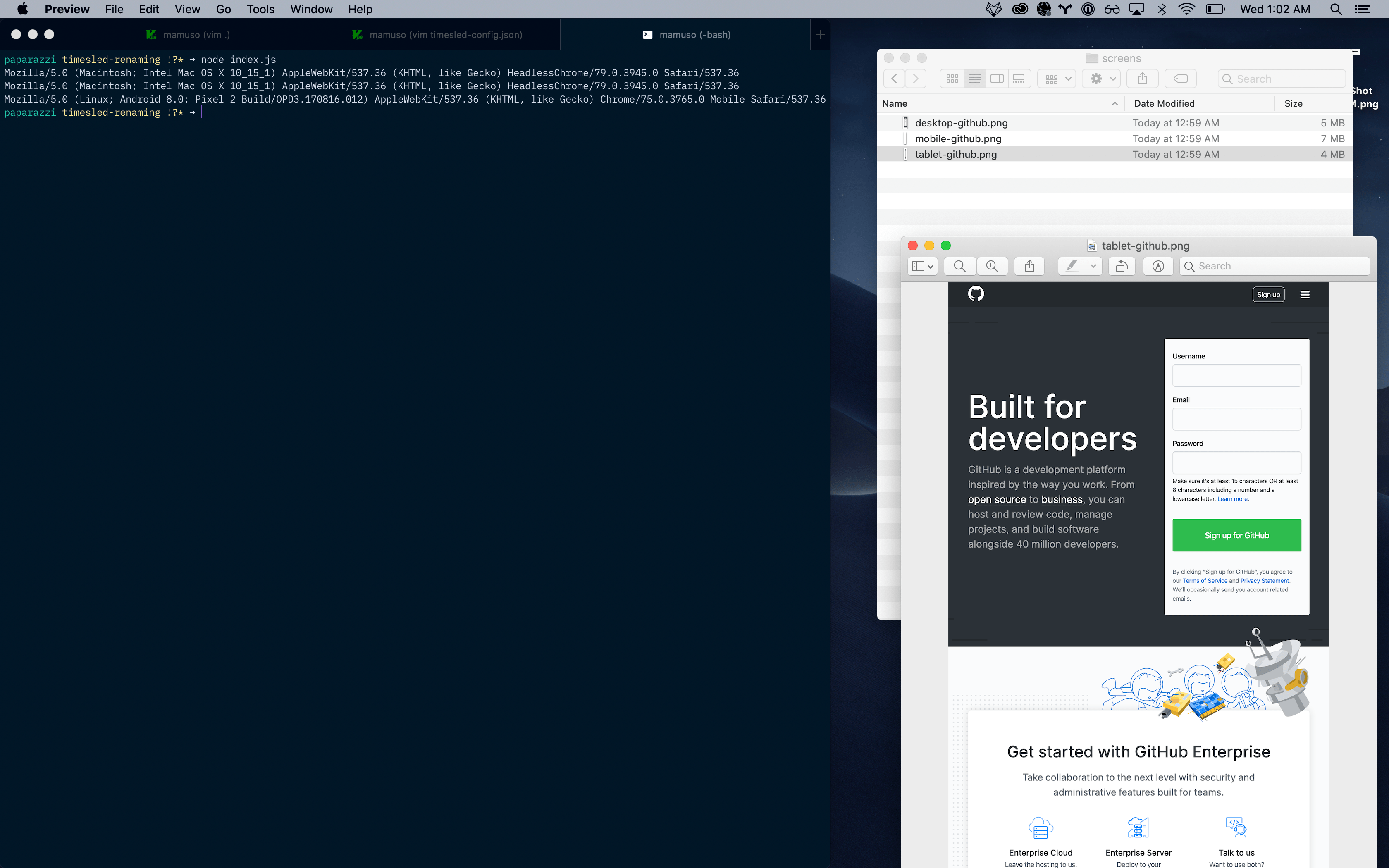
I'm starting a little project to automate the screenshoting of a bunch of endpoints. I want to be able to compare them and go back in time.
A long time ago, I imagined a simpler version of this project, and even registered uihop.com with the intention of builidng a decent service behind it. Years later, during my time at Yammer, Brendan McKeon impressed the whole company with the many uses of his "time machine". I was impressed and inspired by his work, and bummed because that piece of technology wasn't available for more designers.
For now, I started the project creating a very simple action that launches puppeteer inside a docker container and parses a config file with resolutions and a list of URLs.
I read today about a very elegant way of managing dotfiles.
The house, from the roof down
Keeping it veeeery simple.
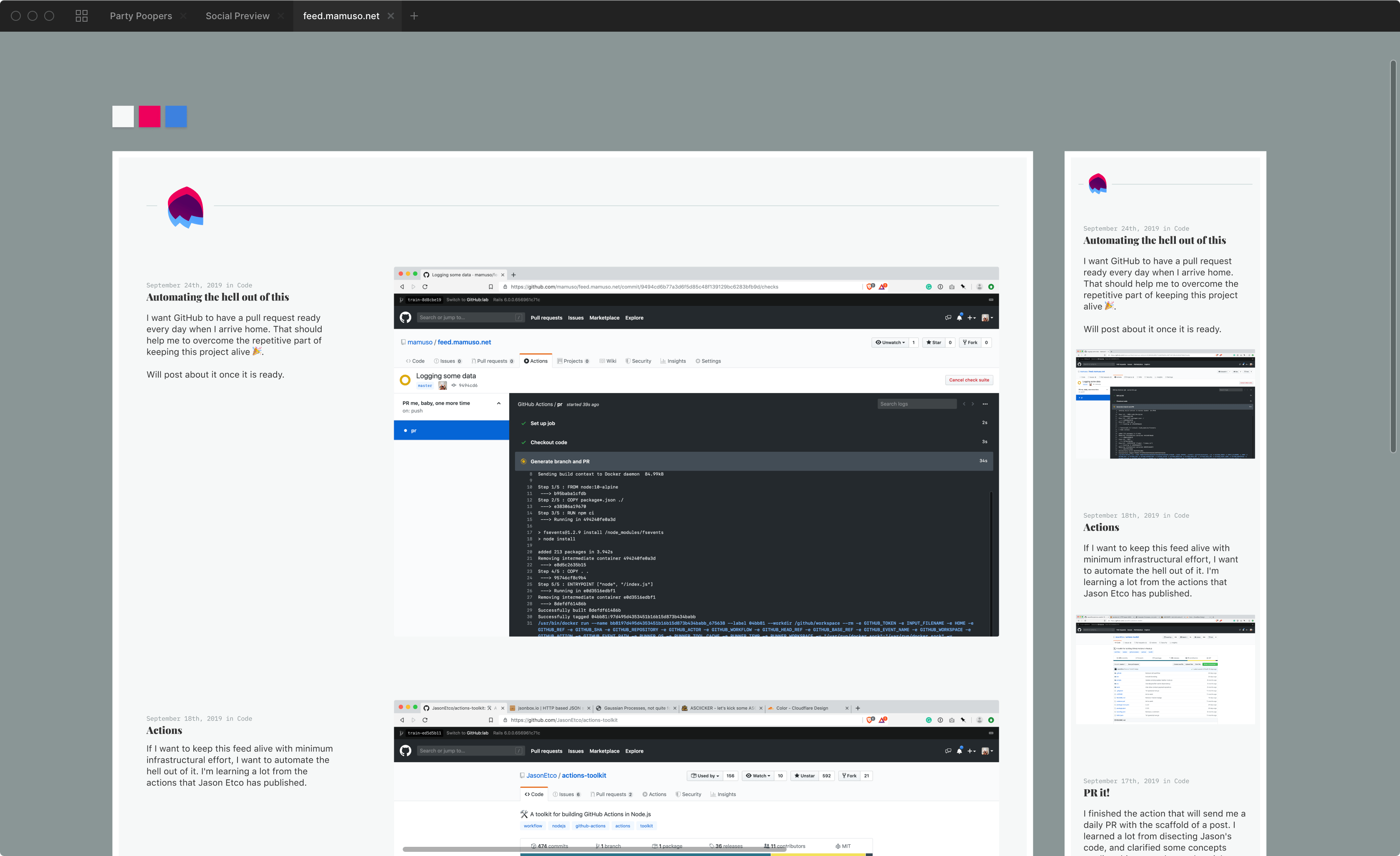
I finished the action that will send me a daily PR with the scaffold of a post. I learned a lot from dissecting Jason's code, and clarified some concepts reading this super thorough article from Jeff Rafter.
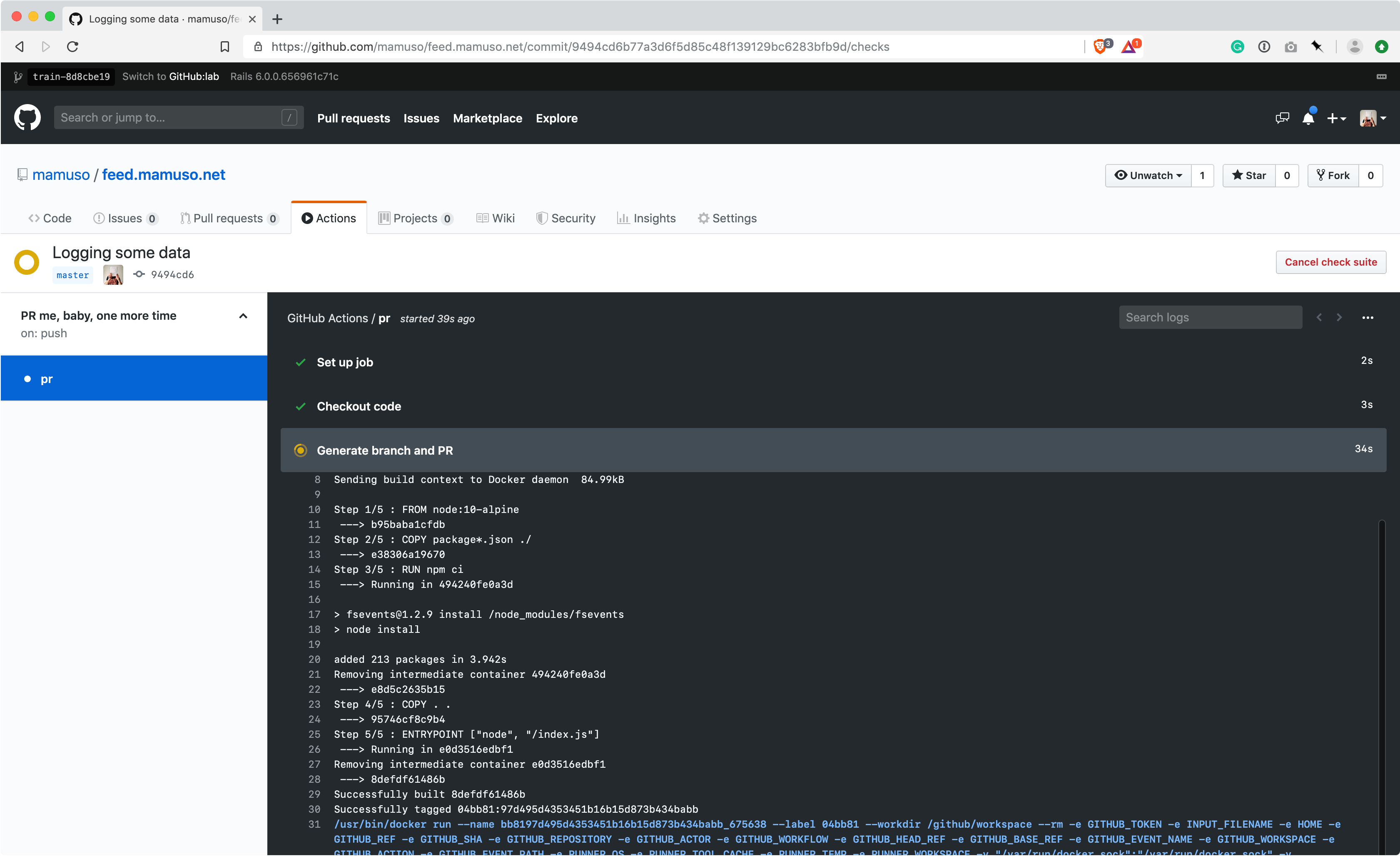
I want GitHub to have a pull request ready every day when I arrive home. That should help me to overcome the repetitive part of keeping this project alive 🎉.
Will post about it once it is ready.
If I want to keep this feed alive with minimum infrastructural effort, I want to automate the hell out of it. I'm learning a lot from the actions that Jason Etco has published.
Feeling inspired by Grant Custer, let's do this!


